
초보자의 GCP 사용기
들어가기 전
본 포스팅은 구글 클라우드 플랫폼 사용자 그룹의 운영진인 Jaeyeon Baek 님과의 스터디에 대한 기록입니다. 또한 이 글은 구글 클라우드 플랫폼 입문 이라는 도서에 대한 리뷰 및 개인적인 스터디 기록임을 미리 밝힙니다.
웹 서비스의 종류
우리가 주로 이용하는 클라우드 서비스, 예를 들어 AWS나 GCP 혹은 Azure와 같은 서비스를 이용하기 전에 기본적으로 알아야 할 것이 있다. 그것이 바로 어플리케이션의 종류와 동작하는 방식 등이다. 그 안에는 웹 어플리케이션과 앱 어플리케이션, HTTP 통신 규약 혹은 데이터베이스에 대한 것들이 포함되어 있다. 이러한 대부분의 것들이 앞으로 학습할 GCP 공부에 도움이 되길 바라며 간단히 정리를 해보았다.
우리가 주로 사용하는 많은 서비스들은 거의 대부분 웹 어플리케이션이나 앱 어플리케이션에 포함되는 경우가 많다. 쇼핑을 위한 이커머스 서비스, 정보 검색을 위한 포털 서비스, 숙박을 위한 배달 앱 서비스 등등 편의를 위한 서비스를 제공해주는 많은 훌륭한 회사들이 많다. 우리가 PC나 모바일 웹에서 도메인을 기반으로 검색하고 들어가는 사이트들은 거의 웹 어플리케이션인 경우가 많다. 반대로 앱스토어에서 다운받은 어플리케이션의 경우에는 네이티브 어플리케이션인 경우가 많다. 하지만 앱스토어에서 받았다고 하더라도 모든 어플리케이션이 네이티브 어플리케이션은 아니다. 요즘은 네이티브 어플리케이션과 반응형 웹을 이용하여 하이브리드 형태로 제작하는 경우도 많다. 그러한 경우는 물론 여러가지 이유가 있겠지만, 개인적으로 생각했을 때 가장 큰 이유 중 하나는 플랫폼 별 리소스 를 집중적으로 관리하기 위해서가 아닐까란 생각을 한다. 네이티브 앱 개발자도 IOS 개발자가 있고 Android 개발자가 있다. 물론 각자 사용하는 프레임워크도 다르고 언어도 다를 수 있다. 이런식으로 플랫폼 별로 리소스를 별도로 관리를 해준다면 버전 관리, 동일한 사용자 경험 부여 등의 문제가 생길 수 있다.
이러한 여러 가지 플랫폼들을 공통적으로 백엔드(Back-end)서버 혹은 API 서버라고 불리는 웹 서버와 요청(Request)와 응답(Response)을 주고 받는다.
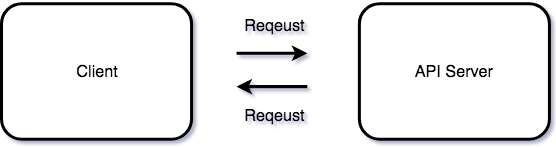
URL와 Method의 종류
이러한 API 서버는 상황에 따라서는 여러 대일수도 있습니다. 클라이언트에서는 어떠한 자원이 필요한지를 알고 원하는 자원에 대한 요청을 합니다. 그러한 원하는 자원은 URL(Uniform Resource Locator)을 지정하게 됩니다.
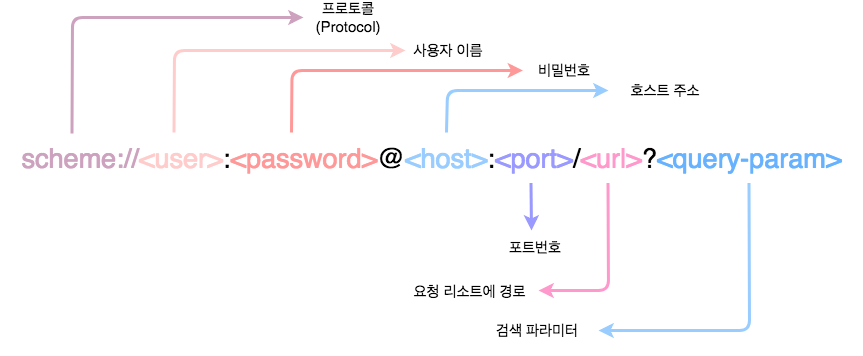
위의 URL 중 사용자 이름(user)와 비밀번호(password), 그리고 포트번호(port) 등 아마 생소한 것들도 있을 것이다. 우리가 URL을 통해 이용하는 많은 웹 사이트들의 경우 사용자 이름이나 비밀번호 같은 경우 생략 되어져있다. 또는 포트번호와 같이 기본 포트(80)로 지정이 되어있거나 포트 포워딩을 통해 우리가 URL만 보고는 쉽게 유추할 수 없는 경우도 많다.
단순히 이러한 URL만 있다고 해서 모든 요청을 API서버에서 알아서 할 순 없습니다. 그래서 우리는 요청에 대한 메소드(Method)와 함께 요청을 보냅니다. 보통 많이 사용하는 Method는 Get, Post, Put, Delete 등이 있으며 종종 Option 메소드도 볼 수 있다. 이러한 메소드와 URI(Uniform Resource Identifier)을 통해 RESTful API 설계를 많이 한다. RESTful API에 대한 이야기는 해당 포스팅 주제가 아니므로 별도로 다루진 않는다. 궁금한 경우는 여기에서 확인할 수 있다.
각 메소드들에 대해서 간단히 설명을 하면 다음과 같이 설명할 수 있다.
| Name | Description |
|---|---|
| Get | 해당 자원을 조회할 때 사용 |
| Post | 해당 자원을 생할 때 사용 |
| Put | 해당 자원을 수정할 때 사용 |
| Delete | 해당 자원을 삭제할 때 사용 |
| Option | Preflight(사전 전달)의 역할을 함으로써 해당 요청 전 해당 자원에 대한 지원여부를 확인할 때 사용 |
이러한 요청에 대한 결과값은 상태(Status)와 함께 응답을 준다.
Status 규약
HTTP Request status codes HTTP 상태 코드는 특정 HTTP 요청에 대한 상태를 나타내준다. HTTP 표쥰 규약의 경우 3자리수로 이루어져 있으며 각자 대역별로 추상적인 의미를 가지게 된다.
Success status(2XX)
해당 상태들은 클라이언트에서 요청한 동작을 수신하여 이해해서 성공적으로 처리했음을 의미 한다.
| Status | Message | Information |
|---|---|---|
| 200 | OK | 요청 성공(단, HTTP method에 따라 성공 의미는 다름) |
| 201 | Created | 요청이 성공하여, 새로운 리소스가 생성(put, post methods에 해당) |
| 202 | Accepted | 요청을 성공적으로 수신하였으나 처리되지 않음. 비동기 처리에서 사용하며 response 에는 결과가 포함되지 않을 수도 있음. |
Redirect status(3xx)
해당 상태들을 클라이언트에서 요청을 한 후, 그 요청을 마무리하기 추가적인 액션을 취해야 함을 의미한다.
| Status | Message | Information |
|---|---|---|
| 301 | Moved Permanently | 요청한 리소스의 URI가 영구적으로 변경되었음을 의미하며, 새로운 URI를 response 에 포함. |
| 302 | Found | 요청한 리소스의 URI가 임시적으로 변경되었으며, 이후에는 요청한 리소스의 URI 로 돌아올 예정임. |
Error in client status(4xx)
해당 상태는 클라이언트의 요청에 뭔가의 오류가 있음을 의미한다.
| Status | Message | Information |
|---|---|---|
| 400 | Bad Request | 클라이언트에 보낸 요청을 서버에서 이해할 수 없음 |
| 401 | Unauthorized | 요청한 리소스에 대한 권한이 없음을 의미(인증되지 않은 경우) |
| 403 | Forbidden | 요청한 리소스에 대한 접근 권한이 없음을 의미하며 401과 다른점은 서버에서는 요청자를 알고 있으나, 인증여부 상관없이 비공개인 경우 |
| 404 | Not Found | 요청한 리소스의 URI가 없음을 의미 |
| 405 | Method Not Allowed | 요청한 리소스의 URI에 요청한 메소드가 정의되어 있지 않을 경우 |
Error in server status(5xx)
4xx는 클라이언트의 오류일 경우라고 한다면, 해당 상태는 서버에 오류가 있음을 의미한다.
| Status | Message | Information |
|---|---|---|
| 500 | Internal Server Error | 서버 내부에 오류가 있어 요청을 수행할 수 없음 |
| 502 | Bad Gateway | 서버가 게이트웨이나 프록시 역할을 하고 있거나 또는 업스트림 서버에서 잘못된 응답을 받음 |
| 503 | Service Unavailable | 서버가 가부하에 걸렸거나, 유지보수를 위하여 접근이 거부 |
데이터 베이스
이전까지 클라이언트와 API서버와의 커뮤니케이션 과정을 살펴보았다. 이제는 어플리케이션의 보다더 뒷단을 살펴볼 필요가 있다. 클라이언트와 API서버가 서로 리소스에 대한 커뮤니케이션 하는 과정에서 일어나는 대부분의 행동은 데이터 베이스에 저장이 된다.

이러한 데이터 베이스에는 크게 두가지 종류가 있다.
관계형 데이터 베이스 관리 시스템 RDBMS
아마 데이터베이스를 사용할 때 제일 많이 이용하는 데이터 베이스가 아닐까 싶다. 데이터베이스 하면 대표적으로 생각나는 Mysql도 이 안에 해당한다. RDBMS는 Relational Database Management System의 약자로서 스프레드시트 같은 형태의 데이터 베이스를 생각하면 이해하기 쉽다. RDBMS는 IBM 산호세 연구소의 에드거 F. 커드가 도입한 관계형 모델을 기반으로 한다. 관계형 데이터 베이스는 만들거나 이용하기가 쉽다. 처음 데이터 베이스는 만든 후 관련되는 응용 프로그램들은 변경하지 않고, 새로운 데이터 항목을 데이터 베이스에 추가 할 수 있다(파일이나 네트웍 데이터베이스 등, 그 이전의 데이터베이스들은 항목이 수정되면, 그 데이터베이스를 사용하는 모든 응용 프로그램도 함께 수정해야하는 어려움이 있었다).
관계형 데이터베이스는 미리 정의된 내용에 따라 테이블들이 구성되는데, 각 테이블은 데이터 종류나 성격에 따라 여러 개의 컬럼(column)이 포함될 수 있다. 예를 들어, 주문거래 데이터베이스에는 성명, 주소, 전화번호 등의 컬럼 항목으로 구성된 테이블과 또한 주문내용(제품, 고객, 일자, 판매가격 등)을 나타내는 테이블이 포함될 수 있다. 이러한 데이터는 사용자의 필요에 맞는 형태로 데이터베이스의 내용을 볼 수 있다. 또한, 관계형 데이터베이스를 구축할 때 데이터 컬럼이 가질 수 있는 값의 범위(domain)나, 그 값에 적용될 수 있는 제한사항(constraint)을 정의할 수 있다. 예를 들어, 고객의 성명을 빈 칸으로 남겨 놓지 못하게 한다거나, 판매가격에는 마이너스(-) 값이 올 수 없도록 제한할 수 있다. 관계형 데이터베이스를 정의하게 되면 그 테이블이나 컬럼, 도메인 및 제한사항에 대한 내용을 가진 메타 데이터(metadata) 테이블이 함께 만들어진다. 이러한 RDBMS를 GCP에서는 Cloud SQL이라는 서비스를 통해 이용할 수 있다.
NoSQL
관계형 데이터 베이스와는 전혀 다른 형태의 데이터 베이스이다. NoSQL은 오랫동안 사용되어진 관계형 데이터와는 다르게 2000년대 초반부터 떠오르기 시작하였다. 과거 빅데이터의 등장에 따라 RDBMS만을 이용해서는 데이터를 처리하는 데 드는 비용의 증가를 막을 수 없었다. 데이터의 양과 트래픽을 한 대에서 실행되도록 설계된 RDBMS의 Scale-up 비용이 기하급수적으로 증가했기 때문이다. 이러한 상황에서 Scale-out을 목표로 등장한 데이터 베이스가 바로 NoSQL이다. 대표적인 데이터베이스로는 Redis나 MongoDB가 포함된다. 주된 데이터 모델의 방식은 KVS(Key-Value Store) 방식이다.
NoSQL은 대규모의 데이터와 트래픽을 위해 설계되었기 때문에 많은 양의 데이터를 다뤄야하는 채팅 데이터나 로그 데이터를 저장하는 데 용이하다. NoSQL은 관계형 데이터 베이스에 비해 유연한 데이터 모델을 사용하며 비정형 데이터를 다룰 때 그 빛을 바랄 수 있다. 또한 key-value 방식의 데이터 모델을 사용하기에 응답 속도나 처리 효율에 있어 뛰어난 성능을 보여준다. 이러한 NoSQL을 GCP에서는 Cloud DataStore와 Cloud Bigtable을 통해 서비스하고 있다.
SQL문
위에서 살펴본 SQL문을 통해 데이터에 접근할 수 있습니다.
- 데이터 정의 언어(DDL: Data Definition Language)
데이터를 저장하는 구조를 정의하기 위한 명령어로서CREATE문(생성),DROP문(삭제),ALERT문(변경)이 이에 해당한다. - 데이터 조작 언어(DML: Data Manipulation Language)
데이터를 조작하기 위한 명령어로서,UPDATE문(변경),DELETE문(삭제),INSERT문(추가),SELECT문(조회)가 이에 해당한다. - 데이터 제어 언어(DCL: Data Control Language)
데이터베이스에 접근 권한 제어나 상태 관리를 하기 위한 명령어로서, 사용자에게 권한을 부여하거나 트랜잭션을 처리할 때 주로 사용합니다.
사실 SQL문 자체를 많이 쓸 일이 없어서일 수도 있겠지만 다른 명령어는 익숙해도 트랜잭션이라는 것이 굉장히 생소했다. 그렇다면 트랜잭션이란 무엇일까?
트랜잭션(Transaction)이란?
위키 백괴에 따르면 데이터베이스 트랜젝션은 데이터베이스 관리 시스템 또는 유사한 시스템에서 상호 작용의 단위 라고 표현하고 있다. 어려운 이 문장을 풀어서 설명하면 데이터베이스 안의 데이터를 변경할 때 하나의 단위로 묶어서 관리하는 구조를 일컫는다. 많은 블로그들과 책에서도 은행의 계좌 시스템이라는 굉장히 좋은 예시로 들어 표현하고 있어 필자도 그림으로 그려 가며 표현해보고자 한다.
만약 다음의 그림과 같이 Man이 Woman에게 $10를 계좌이체 해준다고 가정해보자.
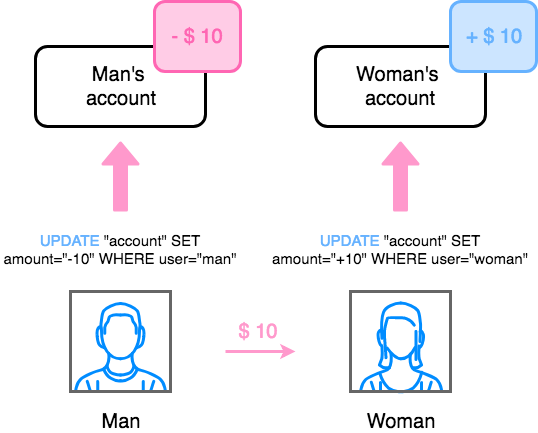
그렇다면 Man의 계좌에 대한 데이터는 -$10에 대한 변경이 일어날 것이고, Woman의 계좌 데이터에서는 +$10에 대한 변경이 일어날 것이다. 이러한 일련의 과정이 하나의 단위로 묶여서 일어나야 한다. 이러한 구조를 트랜잭션이라고 표현한다. 이러한 일련의 과정이 모두 성공적으로 처리가 완료되어 완료된 경우를 COMMIT이라고 표현하고, 만약 하나라도 실패하여 모든 처리를 되돌리는 과정을 ROLLBACK이라고 표현한다. 이러한 특성으로 인해 RDBMS는 아래의 ACID 특성을 필요하다.
- Atomicity(원자성)
트랜잭션에 포함된 처리가 모두 처리가 되거나 혹은 모두 취소가 되어야 한다. - Consistency(일관성)
트랜잭셕 처리 전후로, 모든 데이터의 정합성이 지켜지며, 모순이 없어야 한다. - Isolation(독립성)
트랜잭션 안에서 처리 중인 처리가 다른 처리에 영향을 미치지 않아야 한다. - Durability(내구성)
트랜잭션이 끝났다면 시스템 장애가 생겨도 데이터를 잃지 않아야 한다.
가상화 서버
아마도 MacOS를 사용하는 사용자라면 쉽게 이러한 가상화 서버를 접할 수 있을 것이다. 혹은 다양한 OS에서 어플리케이션을 테스트해야하는 경우에도 접해볼 수 있다. 이러한 가상화 서버는 한 대의 물리 서버를 여러 개의 가상 서버로 나눠서 이용하는 것을 일컫는다. 이러한 가상화 서버는 3개지 형태로 분류할 수 있다.
1. 호스트형 가상화
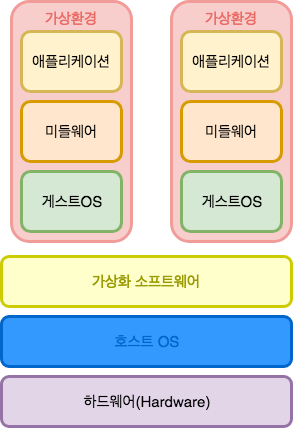
호스트형 가상화는 하드웨어 위의 기반이 되는 호스트 OS(Window, Mac 등)가 존재하며 그 호스트 OS에 가상화 소프트웨어를 설치한다. 이렇게 설치된 가상화 소프트웨어를 통해 서버 하드웨어를 에뮬레이션하는 것이다. 서버 하드웨어를 에뮬레이트하기 때문에 필요한 여분의 CPU 자원,디스크 용량, 메모리 사용량 등과 같은 오버헤드가 커질 수 있지만 게스트 OS에 대한 제약이 없어 대부분의 OS를 동작시킬 수 있다. 이러한 소프트 웨어는 VMware, VirtualBox, Parallels 등이 포함된다.
2. 하이퍼바이저형 가상화
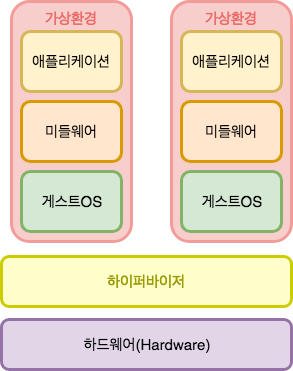
하이퍼바이저형 가상화는 VMM(Virtual Machine Monitor)을 하드웨어 위에서 직접 동작시키기 떄문에 호스트OS 설치가 필요 없다. 호스트 OS에 할당할 리소스가 없기에 호스트형 가상화보다는 오버헤드가 적은게 특징이며 하이퍼바이저가 하드웨어를 직접 제어하기 때문에 리소르르 효율적으로 사용할 수 있습니다. Linux KVM이나 Hyper-v 등이 해당합니다.
3. 컨테이너형 가상화
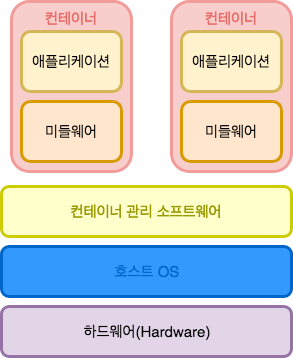
마지막은 컨테이너형 가상화이다. 앞의 두 가상화 서버와는 다르게 각자의 가상환경에 게스트 OS가 존재하지 않기 때문에 오버헤드가 적으며 가볍고 빠르게 동작하는 것이 특징이다. 호스트 OS위에 컨테이너 기반으로 분리해두고 각가에 독립된 OS 환경을 제공해준다. 이러한 컨테이너는 HostOS를 다른 컨테이너들과 공유한다. Docker가 대표적인 컨테이너 가상화 기술을 사용합니다.